

汉王PDF文字识别软件,汉王PDF OCR,识别率非常高,而且识别速度足够快,为广大PDF文字录入人遇提供高效的识别服务,识别速度快特点的OCR图片文字识别软件,它支持批量处理功能,避免了单页处理的麻烦。汉王OCR支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;可识别简体、繁体和英文三种语言;具有简单易用的表格识别功能;具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件。
汉王PDF文字识别软件介绍
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
汉王PDF文字识别软件功能
1.图像输入,图像预处理,预识别。
2.图像输入。
目前有OpenCV、Cximage等开源项目,存储格式不同,压缩方式不同。
3.预处理
主要包括二值化、噪声去除、倾斜等。
4.二值化
摄像头拍摄的图片大多是彩色图像,信息量巨大。图片的内容可以简单地分为前景和背景。为了使计算机更快更好地识别文本,我们需要首先处理彩色图片,使图片只有前景信息和背景信息,前景信息可以简单地定义为黑色,背景信息为白色,这是二值图。
5.去除噪音。
对于不同的文档,噪声的定义可以不同,根据噪声的特点,称为噪声去除。
6.倾斜校正。
由于一般用户在拍照文档时比较随意,拍照的图片不可避免地会倾斜,这就需要文本识别软件进行更正。
7.布局分析。
分段文档图片的过程称为布局分析。由于实际文档的多样性和复杂性,目前还没有固定的最佳切割模型。
八、字符切割。
由于拍照条件的限制,字符粘连和断笔往往受到极大限制。
9.字符识别。
这项研究已经很早了,模板匹配相对较早,然后主要是特征提取。由于文本位移、笔画厚度、断笔、粘连、旋转等因素,特征提取的难度受到很大影响。
10.还原布局。
人们希望识别后的文本仍然像原始文档图片一样排列,段落不变,位置不变,顺序输出到Word文档、PDF文档等,这个过程称为布局恢复。
11.后处理,校对。
根据特定语言的上下文关系,校正识别结果,即后处理。
汉王PDF文字识别软件使用方法
1.在开始菜单中打开OCR软件。
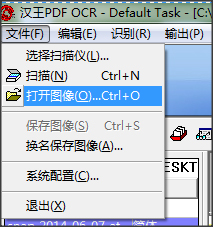
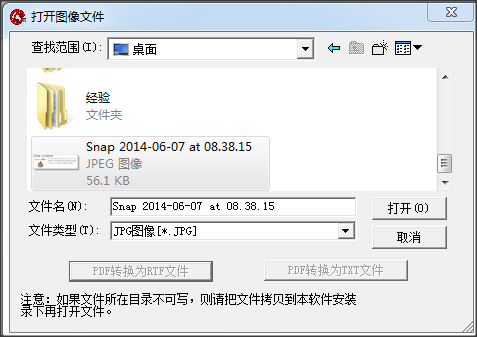
2.点击【文件】-【打开图像文件】,选择一副包含文字的图片。
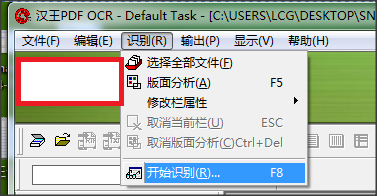
3.点击【识别】-【开始识别】。
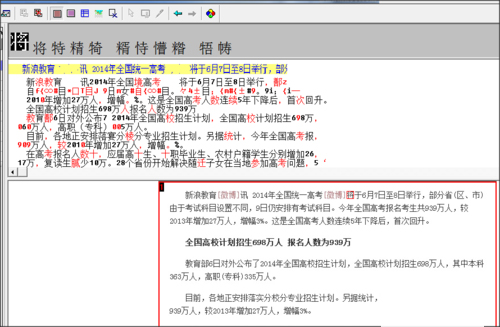
4.软件会识别出图片上的文字,可以对一些识别错误的字进行修改。
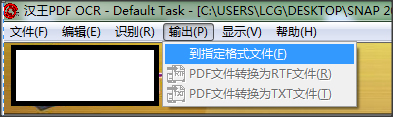
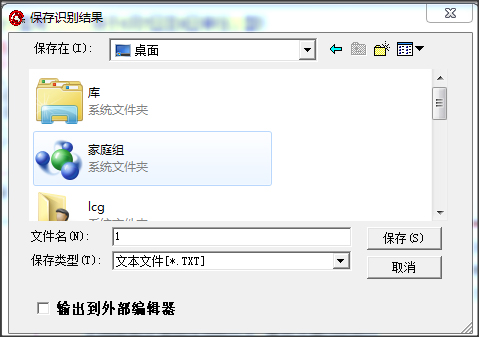
5.修改完成后点击【输出】-【到指定格式】,保存识别出来的文本。
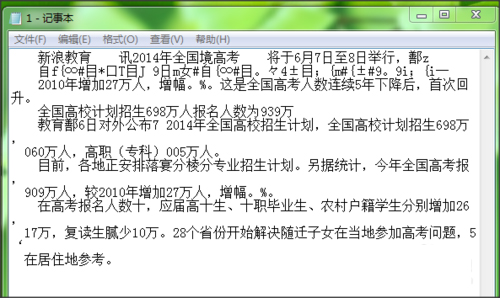
6.可以打开保存的文本,将文本复制到word等软件处进行二次编辑。
更新日志
对部分功能进行了优化。
上一篇:DikDik影音转霸
下一篇:阿里云盘PC客户端
 WPS2019个人免费版|WPS Office 2019免费办公软件V11.1官方版
WPS2019个人免费版|WPS Office 2019免费办公软件V11.1官方版 QQ浏览器2021 v10.4绿色版精简版(去广告纯净版)
QQ浏览器2021 v10.4绿色版精简版(去广告纯净版) 酷我音乐盒下载|下载酷我音乐盒 2021 官方免费版
酷我音乐盒下载|下载酷我音乐盒 2021 官方免费版 酷狗音乐播放器|酷狗音乐下载安装 V2022官方版
酷狗音乐播放器|酷狗音乐下载安装 V2022官方版 360驱动大师离线版|360驱动大师网卡版官方下载 v2022
360驱动大师离线版|360驱动大师网卡版官方下载 v2022 【360极速浏览器】 360浏览器极速版(360急速浏览器) V2022正式版
【360极速浏览器】 360浏览器极速版(360急速浏览器) V2022正式版 【360浏览器】360安全浏览器下载 官方免费版2021 v13.1.1482
【360浏览器】360安全浏览器下载 官方免费版2021 v13.1.1482 【优酷下载】优酷播放器_优酷客户端 2019官方最新版
【优酷下载】优酷播放器_优酷客户端 2019官方最新版 腾讯视频下载|腾讯视频播放器官方下载 v2022最新版
腾讯视频下载|腾讯视频播放器官方下载 v2022最新版 【下载爱奇艺播放器】爱奇艺视频播放器电脑版 2022官方版
【下载爱奇艺播放器】爱奇艺视频播放器电脑版 2022官方版 2345加速浏览器(安全版) V10.7.0官方最新版
2345加速浏览器(安全版) V10.7.0官方最新版 【QQ电脑管家】腾讯电脑管家官方最新版 2022 v15.2
【QQ电脑管家】腾讯电脑管家官方最新版 2022 v15.2 360安全卫士下载【360卫士官方最新版】2021_v13.0
360安全卫士下载【360卫士官方最新版】2021_v13.0 office2007破解版|Office 2007破解完整免费版
office2007破解版|Office 2007破解完整免费版 系统重装神器|飞飞一键重装系统软件 V2.4正式版
系统重装神器|飞飞一键重装系统软件 V2.4正式版